PaddlePaddle
PaddlePaddle é uma plataforma de Aprendizado de Máquina que combina métodos de Deep Learning com algoritmos distribuídos desenvolvida pelo grupo de cientistas e engenheiros do Baidu. PaddlePaddle provê uma interface intuitiva e flexível facilitando o carregamento do dados e especificação da estrutura do modelo. Para garantir maior eficiência PaddlePaddle utiliza os algoritmos do estado-da-arte combinado com técnicas de otimização em todos os níveis. Atualmente é utilizada em mais de 30 serviços online e offline da Baidu.
O código fonte do PaddlePaddle está disponível no repositório oficial do Baidu no GitHub desde 31 de Agosto de 2016. Na primeira semana 88 commits foram realizados, e no mês de Setembro de 2016 teve uma média de mais de 31 commits diários em média. A equipe de desenvolvimento é composta por 13 contribuidores e conta também com a colaboração de usuários na detecção de bugs e sugestão de melhorias. Atualmente o código é distribuído sobre a licença Apache-2.0.
- Deep Learning
- Ferramentas e Linguagens
- Equipe de desenvolvimento
- Arquitetura
- Evolução
- Como contribuir
- Instalação
- Exemplificação de Uso
- Referências
Deep Learning
Deep Learning são técnicas robustas de Redes Neurais que compõem hoje o estado-da-arte dos algoritmos de Aprendizado de Máquina. Ao invés de extrair atributos dos dados como nas técnicas tradicionais, Redes Neurais permitem que os objetos de interesse possam ser os dados de entradas. Por exemplo na tarefa de reconhecimento de objetos, ao invés de entregar ao modelo características de uma imagem pode-se usar a própria imagem como entrada e a Rede Neural será capaz de identificar os padrões da imagem que permitam detectar os objetos.
A Rede Neural tradicional utiliza camadas de entrada, camadas ocultas e camadas de saída, cujo treinamento é feito através do algoritmo de backpropagation. As técnicas de Deep Learning modificam alguma parte desse modelo e conseguem aumentar os ganhos de acurácia significativamente. Por exemplo, a Convolutional Neural Networks basicamente limita a "visão" das camadas ocultas, de forma que os neurônios não vêem toda a entrada e as camadas ocultas sofrem transformações durante a execução. Outras modificações incluem variar o alcance das camadas ocultas e alterações na aplicação do backpropagation. As técnicas mais famosas de Deep Learning incluem:
- Restricted Boltzmann Machines (RBM)
- Deep Belief Nets
- Convolutional Neural Networks
- Recurrent Neural Networks
- Autoenconders
- Recursive Neural Tensor Net
Ferramentas e Linguagens
O Projeto do GitHub do PaddlePaddle utiliza diversas linguagens de programação no projeto, sendo as duas principais sendo Python e C Plus Plus (C++). Esse projeto possui duas versões diferentes de código, cada uma apoiada sobre uma linguagem, sendo que uma delas apresenta características que a torna um pouco mais potente que a outra, possibilitando ao programador assim a utilização da versão que mais se adapte ao que ele deseja ou a mais adequada à sua aplicação.
A versão escrita em Python permite que o programa principal compilado em C++ possa ser executado dentro de um script Python facilitando o pré-processamento. A biblioteca em Python também é considerada uma vantagem devido a grande popularização recente da linguagem.
Os códigos criados com essa linguagem enquadram a programação das funcionalidades de uma biblioteca de Deep Learning como o PaddlePaddle, que se localiza dentro da pasta py_paddle, um servidor de interação com a biblioteca, totalmente feito em Python e os scripts de instalação no Sistema Operacional Ubuntu (Linux).
Dentro das funcionalidades da biblioteca com Python, se enquadram os códigos de DataProvider (pasta PyDataProvider) que é utilizado para ler dinamicamente qualquer tipo de dados, não importando o formato. Possuindo um processo extremamente flexível e customizável, o que acaba sacrificando um pouco a eficiência do código.
A principal ferramenta externa utilizada no Projeto PaddlePaddle é o CUDA, Compute Unified Device Architecture, desenvolvido pela NVIDIA para tirar o maior proveito das unidades de processamento gráfico e auxiliar na resolução de muitos problemas complexos em uma fração do tempo necessário em uma CPU.
A versão que utiliza a linguagem C++ possui uma integração com a ferramenta CUDA, Compute Unified Device Architecture. Essa versão do PaddlePaddle possui uma eficiência maior por não permitir tanta customização como a biblioteca projetada em Python permite. Essa versão possui um servidor próprio, localizado em gserver. Todos os recursos da plataforma estão disponíveis em ambas versões.
C++ é utilizada em todo o projeto, tendo código escrito para o servidor, a api, as funções matemáticas e na parte de variáveis que permitem o rastreamento remoto dos parâmetros do código. O Código em C++ também é customizável, mas de forma diferente a do código em Python. Sendo a customização dessa versão voltada para o uso mais completo ou para aumentar a eficiência do código. A proporção de cada imagem utilizada é apresentada no gráfico abaixo:

Equipe de desenvolvimento
O Sistema do PaddlePaddle desenvolvido pela Baidu é um projeto Open Source, tendo o seu código distribuído através do GitHub. A ferramenta vem sendo desenvolvida e evoluída ao longo do tempo, possuindo diversos Stakeholders envolvidos no projeto. Os Stakeholders podem ser segmentados nos grupos:
Desenvolvedores: Consiste principalmente dos colaboradores do GitHub, sendo os quatro principais, ou seja, os colaboradores que mais submeteram uma nova versão, assim adicionando novas funcionalidades ao projeto no GitHub. Além dos colaboradores do GitHub, o projeto do PaddlePaddle possui os funcionários relacionados a empresa chinesa Baidu, que é uma empresa de pesquisas abertas e que possui em seu portfólio diversos projetos no formato Open Source, e é a responsável pelo desenvolvimento inicial do projeto PaddlePaddle. Os principais desenvolvedores assíduos do projeto são os usuários Gangliao, Reyoung, Qingqing01 e Luotao1.
Usuários: Consiste principalmente por usuários que possuem conhecimento avançado e intermediário na área de computação, como programadores que utilizam o PaddlePaddle para auxiliar na implementação de um sistema de ´Parallel Distributed Deep Learning”.
Mantedores: Os principais mantedores do projeto vivo são os seus desenvolvedores da empresa Baidu, mas o GitHub é a fonte principal de distribuição do projeto e é graças a ele que o projeto continua vivo, uma vez que o repositório permite que diversos programadores invistam o seu tempo e dinheiro na melhoria do projeto.
Equipe de Suporte: Consiste principalmente de voluntários, dos colaboradores do GitHub e dos desenvolvedores da empresa.
Testadores: Os principais testadores são os voluntários do projeto, que o testam e reportam todos os seus erros no sistema de erros presente no GitHub, sistema que auxiliam no controle e solução mais eficiente desses erros. Como o projeto é um sistema Open Source não existe uma equipe de teste específica, pois são os seus próprios desenvolvedores que fazem esse trabalho.
Assessores: São representados pela equipe de desenvolvimento da própria empresa Baidu, onde cada integrante verifica todos os envios do projeto ao GitHub e analisa como que está o projeto para a realização de planos futuros.

Arquitetura
Entre as funcionalidades da ferramenta PaddlePaddle, a principal delas é a construção de Redes Neurais Artificiais que possibilitam um resultado satisfatório em diversas aplicações ligadas a Aprendizado de Máquina, como por exemplo reconhecimento de escrita, tradução, reconhecimento de voz, análise de sentimentos, reconhecimento de imagens e vídeo, sistemas de recomendação, processamento de linguagem natural, entre outras. Cada uma dessas redes possui uma arquitetura específica que se adequam ao seu caso de uso. Além disso elas possuem hiperparâmetros próprios que fazendo com que o uso delas mais indicado para uma aplicação ou um conjunto de dados específicos. Abaixo são relacionados os principais modelos de redes neuronais e seu funcionamento genérico. As configurações de seus hiperparâmetros podem alterar de maneira substancial cada uma das redes fazendo com que, por exemplo, duas redes neurais convolucionais apresentem desempenho bastante diferente em relação ao mesmo conjunto de dados. Deste modo, a existência de hiperparâmetros faz com que cada rede neural seja quase única, ampliando significativamente o número de funcionalidades do software PaddlePaddle.
Regressão Logística
Regressão Logística é uma técnica estatística que pode ser usada tanto para classificação quanto para predição. Uma Regressão Logística pode ser vista como uma Rede Neural sem camadas ocultas contendo apenas a camada de entrada e a camada de saída, sendo a camada de entrada os atributos dos itens e a camada de saída um único neurônio. Uma Rede Neural de Regressão Logística no PaddlePaddle é uma Rede Neural onde toda camada é completamente conectada a camada seguinte resultando na Rede Neural comum, como a que é demonstrada na imagem:

No processo de classificação de texto utilizando uma Rede Neural de Regressão Logística tem-se um texto de entrada cujas palavras são submetidas a um método de conversão de representação de palavras (Word Representation) e depois de convertidas são novamente transformadas para manter suas relações como sentenças (Sentence Representation). Se a entrada já está classificada, a plataforma executará automaticamente no modo de treinamento calibrando o modelo de acordo com uma função de peso (Classification Loss Function) com o objetivo de minimizar o erro. Quando o modelo estiver treinado, um teste é executado para calcular a acurácia (Accuracy) do modelo. Tanto o treinamento quanto o teste exigem entradas cuja classificação é conhecida. A representação gráfica do modelo é apresentada no diagrama abaixo:

Word Embedding Model
A técnica de Word Embedding ou Mergulho Lexical é um método de aprendizagem que se foca no aprendizado de uma representação das palavras. Essa técnica permite representar palavras de um dicionário através de vetores afim de facilitar a análise semântica e sintática. Desse modo, cada palavra é representada por um vetor de números reais, e as palavras que aparecem em contextos similares terão uma representação vetorial mais próxima entre si do que aqueles que aparecem em contextos diferentes. Por meio dessa nova representação é possível diminuir consideravelmente o espaço de dimensionalidade, uma vez que não se estoca mais o dicionário inteiro porém, unicamente, um espaço de vetores. Através dessa técnica foi possível melhorar consideravelmente certos campos de aplicação, dentro os quais podemos citar: tradução, análise de sentimentos e reconhecimento de voz. Um exemplo de uso do modelo Word Embedding pode ser visto no esquema abaixo, onde a partir da palavra xk é possível prever em quais contextos {y1j,...,yCj} esta palavra está inserida.

O processo de classificação de texto utilizando a modelo de Word Embedding é muito similar ao processo que utiliza regressão logística. A grande diferença é que, enquanto esse modelo usa vetores de representação lexical para representar as palavras, o modelo de regressão logística utiliza vetores esparsos. Como no modelo de Regressão Logística, as palavras são convertidas em um vetor de representação (Word Representation e Word Embedding) e posteriormente transformadas para manterem suas relações sintáticas(Sentence Representation). É feita então a calibragem do modelo para minimizar o erro (Classification Loss Function) e, na fase de teste, é calculado o grau de acerto (Accuracy) do modelo. A representação gráfica do modelo é apresentada no diagrama abaixo:

Rede Neural Convolucional
A Rede Neural Convolucional é um tipo de rede neural artificial feed-foward, onde os percéptrons usam os resultados antecipados das redes intermediárias e vão modificando o processo de aprendizagem, de modo semelhante ao processo biológico de visão. Nesse tipo de rede, a informação move em uma única direção (para frente) dentro das unidades da rede (percéptrons). Esses percéptrons, que se dividem em camadas que são totlamente conectadas, identificam aspectos de sobreposição de características para que se possa extraí-las dos dados. Essa técnica é usada em uma vasta quantidade de aplicações relacionadas a reconhecimento de imagem e vídeo e processamento de linguagem natural. Nesse último caso, uma aplicação possível é a de identificar, em um conjunto de sentenças, quais carregam aspectos positivos ou negativos a partir do contexto em que elas estão inseridas. A figura abaixo mostra como funciona um processo de Convolução: cada uma das camadas de uma rede extrai certas características de um informação (convolution + nonlienarity), posteriormente reduz-se a dimensionalidade das características extraídas avaliando as informações circunvizinhas (max pooling); a partir da relação entre as diversas informações, classifica-se as informações da maneira desejada.

Uma Rede Neural Convolucional para classificação de texto converte uma sequência de representações lexicais (Word Embedding) numa representação da sentença usando convolução temporal. Primeiramente toma-se os k contextos mais próximos de uma palavra em uma sentença e os empilha em uma representação vetorial bidimensional (Word Context). Depois se faz uma convolução temporal nessa representação para produzir um vetor com as dimensões ocultas dos dados (Convolution), e aplica-se a redução de dimensionalidade (Max Pooling) para os novos vetores para obter a nova representação da sentença. O modelo é calibrado a fim de minimizar o erro na fase de treino (Classification Loss Function) e, na fase de teste, é calculado a sua acurácia (Accuracy). Segue abaixo um diagrama que representa esse modelo de rede:

Rede Neural Recorrente
Uma Rede Neural Recorrente é um tipo de rede onde suas unidades são conectadas de maneira a formar ciclos direcionados. Ao contrário das redes neurais feed-foward, as redes recorrentes podem usar sua memória interna para processar sequências arbitrárias de entradas. Os modelos de Redes Recorrentes são bastante recentes e têm mostrado bom desempenho em aplicações envolvendo reconhecimento de fala e escrita. Uma importante rede recorrente é a LSTM que tem se mostrado bastante adequada para aprender a classificar e predizer séries temporais quando existem longos intervalos de tempo de tamanho desconhecido entre eventos importantes. Outro modelo atual é o GRU, muito similar ao LSTM, porém com menos parâmetros. Abaixo está um típico modelo de rede recorrente LTSM.
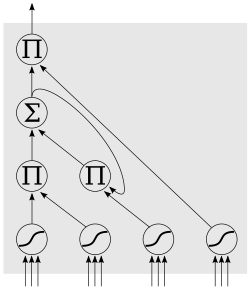
Entre as bibliotecas contidas no PaddlePaddle, encontramos ferramentas para modelos de Redes Recorrentes Simples, modelo de série temporal, modelo GRU e LSTM. Por não ser uma rede cíclica, diferente da rede de convolução, no que se refere à classificação textual, a arquitetura do Modelo Recorrente se difere da arquitetura do Modelo de Rede Neural Convolucional na representação do contexto e na convolução. Esses passo não existem na rede recorrente, já que eles são substituidos pelo pao próprio modelo de Recorrência (Recurrent). Após as palavras terem passado por um método de conversão de representação de palavras (Word Embedding), elas estão são submetidas ao modelo de Recorrência (Recurrent) onde serão extraídas as características da informação que estão ocultas e então é aplicado a redução de dimensionalidade(Max Pooling) e os demais passos de maneira semelhante à arquitetura do Modelo das Redes Neurais Convolucionais. O diagrama abaixo ilustra de maneira clara como se dá o processo.

Evolução
Em 31 de Agosto de 2016 foi disponibilizada a primeira versão pública da plataforma sob a identificação v0.8.0beta.0. Para a primeira versão a comunidade envolvida reportou 13 questões (issues), das quais 5 eram sobre adição de funcionalidades, 2 de bugs e 3 de esclarecimento. Duas das questões de esclarecimento se referiam ao processo de compilação da plataforma e a outra sobre as referências dos algoritmos implementados. Questões como essas deveriam estar respondidas na documentação evidenciando que a documentação não era satisfatória na primeira versão.
A versão v0.8.0beta.1 foi publicada no dia 29 de setembro. As novidades da versão são demonstradas no quadro abaixo. As mudanças incluem suporte ao sistema Mac OSX, suporte ao processamento CUDA, outras melhorias da camada de hardware e "mais documentação". Até o dia 8 de Outubro a versão beta.1 teve 66 questões (issues) reportados das quais 16 são de esclarecimento. Reforçando ainda mais a necessidade de uma documentação mais clara e objetiva.
New features:
Mac OSX is supported by source code.
#138
- Both GPU and CPU versions of PaddlePaddle are supported.
Support CUDA 8.0
Enhance
PyDataProvider2
- Add dictionary yield format.
PyDataProvider2can yield a dictionary with key is data_layer's name, value is features.
- Add
min_pool_sizeto control memory pool in provider.Add
debinstall package & docker image for no_avx machines.
- Especially for cloud computing and virtual machines
Automatically disable
avxinstructions in cmake when machine's CPU don't supportavxinstructions.Add Parallel NN api in trainer_config_helpers.
Add
travis cifor GitHubBug fixes:
- Several bugs in trainer_config_helpers. Also complete the unittest for trainer_config_helpers
- Check if PaddlePaddle is installed when unittest.
- Fix bugs in GTX series GPU
- Fix bug in MultinomialSampler Also more documentation was written since last release.
Métricas
Utilizando-se o programa cloc pode-se calcular automaticamente algumas métricas entre as duas versões. A tabela abaixo apresenta o número de arquivos, o número de comentários e o LOC (lines of code) das duas versões. Considerando as métricas da tabela pode-se dizer que a evolução da plataforma foi pequena, mas aceitável devido ao curto tempo entre as versões.
| Métricas | 0.8.0beta0 | 0.8.0beta1 | Comparativo |
|---|---|---|---|
| Arquivos | 551 | 590 | 1,07% |
| Comentários | 24534 | 25077 | 1,02% |
| LOC | 74414 | 76265 | 1,02% |
| Lançamento | 31/08/2016 | 29/09/2016 | 29 dias |
Como contribuir
Quando Baidu disponibilizou PaddlePaddle como código aberto permitiu que diversos desenvolvedores tivessem acesso a uma plataforma robusta de Deep Learning. Mais do que utilizar o PaddlePaddle, desenvolvedores podem também contribuir reportando falhas e sugerindo funcionalidades. Essa contribuição pode ser na forma de questão (issue) ou de código.
Para ter o pull request aceito é necessário seguir os requerimentos:
- Seu código deve ser documentado utilizando dozygen style.
- Seu código deve passar o teste de estilo quando a opção
WITH_STYLE_CHECKno compilador está habilitada. - Todo o código deve conter testes unitários e ser aprovado em todos.
Diretrizes para contribuir
1.Vá para a https://GitHub.com/baidu/Paddle e clique em Fork.
2.Clone o repositório para sua máquna local utilizando o comando:
git clone https://GitHub.com/USERNAME/Paddle.git
3.Crie um branch local utilizando o comando:
git checkout -b MY_COOL_STUFF_BRANCH origin/master
4.Para adicionar arquivos ao branch utilize os comandos:
git add FILENAME
git commit -m "commit info"
5.Antes de submeter um pull request certifique se que você possui a versão mais recente do repositório utilizando o comando:
git pull --rebase upstream HEAD
6.Quando estiver pronto para submeter suas alterações utilize o comando
git push origin HEAD
7.Vá para a https://GitHub.com/baidu/Paddle e clique em New pull request.
Observação: se alterações forem feitas no código principal depois de seu pull request você pode atualizar sua requisição clicando em Update branch na página da requisição no repositório. Se não houverem conflitos o GitHub atualizará seu código automaticamente. Caso contrário é necessário fazê-lo manualmente utilizando os comandos:
git checkout MY_COOL_STUFF_BRANCH
git pull --rebase upstream HEAD
git push -f origin HEAD
Instalação
As versões PaddlePaddle estão divididas em 2 grupos de categorias não excludentes. Uma das categorias especifica a unidade de processamento: CPU ou GPU. Intuitivamente, a versão GPU é mais eficiente no consumo de recursos computacionais. A outra categoria também está ligada ao hardware: suporte à AVX. AVX é um conjunto de instruções especiais proposto pela Intel em 2008. Esse conjunto de instruções permite ao processador executar tarefas complexas num tempo menor. Para verificar se uma máquina suporta AVX utilizando o comando:
if cat /proc/cpuinfo | grep -q avx ; then echo "Support AVX"; else echo "Not support AVX"; fi
Instalação usando Docker
As versões do PaddlePaddle no repositório do Docker são identificadas pelos nomes:
cpu-latestCPU e sem suporte AVXgpu-latestGPU e sem suporte AVXcpu-noavx-latestCPU e com suporte AVXgpu-noavx-latestGPU e com suporte AVX
Sem suporte GPU
Execute o comando substituindo [VERSION] pelo identificador da versão no Docker:
docker run -it paddledev/paddle:[VERSION]
Com suporte GPU
Substitua [VERSION] pelo identificador da versão no Docker, utilize o comando:
export CUDA_SO="$(\ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(\ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
docker run ${CUDA_SO} ${DEVICES} -it paddledev/paddle:[VERSION]
Instalação usando pacote Debian
A instalação usando pacote Debian segue o procedimento comum para esse tipo de pacote. Faça o download do pacote Debian da página de releases do projeto no GitHub. Depois execute o comando no diretório onde o pacote se encontra:
dpkg -i paddle-*.deb
apt-get install -f
Exemplificação de Uso
Para a utilização do PaddlePaddle são seguidos alguns passos específicos, para que o programa funcione de forma desejada. Através dessa ferramenta é possível realizar a classificação de qualquer tipo de dados. Suponha que se deseje avaliar, em um site de compras na Web, os sentimentos dos usuários de um produto a partir dos comentários deixados por eles na página sobre a qualidade do referido produto. É necessário então a construção de um Sistema de Classificação Textual, que permitirá analisar uma frase e a classificar adequadamente de acordo com o sentimento expresso nela.
Para se construir esse Sistema de Classificação de Textual são seguidos cinco passos:

Processar os dados em um formato normalizado.
a) No exemplo de texto de classificação, você deve iniciar um arquivo de texto com um exemplo de treinamento por linha, contendo uma ID, denominado como alvo Y, seguido pelo texto, denominado como alvo X, onde cada “alvo” é separado por uma Tab. (Y [tab] X).Fornecer dados para o Modelo de Aprendizado
a) É permitido a criação dos dados em Python, caso seja necessário o uso de pré-processamento dos dados, esses passos são adicionados ao arquivo PyDataProvider.
b) O Texto de Classificação criado passa a ser considerado um dicionário, onde cada palavra possui um ID específico que é utilizado pelo arquivo PyDataProvider.
c) Para que funcione corretamente, é necessário adicionar a definição do DataProvider nas configurações da rede, para assim especificar:
i. O caminho de exemplificação dos dados
ii. O local do arquivo de dados
iii. A função para chamar o processo
iv. Os argumentos que não passados para o dicionário.
from paddle.trainer_config_helpers import *
file = "data/dict.txt"
word_dict = dict()
with open(dict_file, 'r') as f:
for i, line in enumerate(f):
w = line.strip().split()[0]
word_dict[w] = i
# define the data sources for the model.
# We need to use different process for training and prediction.
# For training, the input data includes both word IDs and labels.
# For prediction, the input data only includs word Ids.
define_py_data_sources2(train_list='data/train.list',
test_list='data/test.list',
module="dataprovider_bow",
obj="process",
args={"dictionary": word_dict})
Especificar uma Estrutura de Rede Neural para o PaddlePaddle, que podem ser um dos seguintes tipos:
a) Um modelo de regressão logística.
b) Um modelo Word Embedding.
c) Um modelo de rede neural convolucional.
d) Um modelo de rede neural recorrente sequencial.Treinar o Modelo. Nesse caso, rotular uma parte dos dados para identificar, num número finito e pequeno de possibilidades, em qual sentimento cada comentário se traduz.
Inferir, isto é, avaliar o modelo sobre o conjunto de dados não treinados. Após a inferência textual é verificado seu grau de precisão a fim de precisão quão acurado é o modelo.
Referências
- baidu/Paddle. GitHub. Disponível em: https://GitHub.com/baidu/Paddle. Acesso em: 10 out. 2016.
- LSTM | Wikiwand. Wikiwand. Disponível em: http://www.wikiwand.com/zh-hk/LSTM. Acesso em: 10 out. 2016.
- PaddlePaddle - PArallel Distributed Deep LEarning. Paddlepaddle.org. Disponível em: http://www.paddlepaddle.org/. Acesso em: 10 out. 2016.
- PaddlePaddle Documentation. Paddlepaddle.org. Disponível em: http://www.paddlepaddle.org/doc/index.html. Acesso em: 10 out. 2016.
- Rob Hess, and Friends. Introducing: Flickr PARK or BIRD. Disponível em: http://code.flickr.net/2014/10/20/introducing-flickr-park-or-bird/. Acesso em: 10 out. 2016.
- Word embedding. Fr.wikipedia.org. Disponível em: https://fr.wikipedia.org/wiki/Word_embedding. Acesso em: 10 out. 2016.